PPO squared-error loss #1
Comments
|
The pytorch version loss function is referenced from here. |

Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
|
The pytorch version loss function is referenced from here. |
想請問下PPO value loss的計算方法,因為PPO paper上好像沒定義很清楚squared-error loss的計算( 有點不太能理解?)
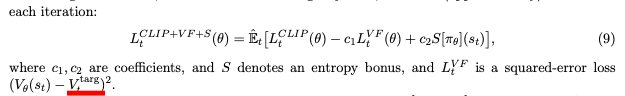
我發現你在 ADL, MLDS 兩邊的PPO squared-error loss 計算方式不大一樣,然後我看了網路上很多寫法(tensorlayer等等)也都不大相同,想請問下這方便你是怎麼理解的?謝謝
ADL hw3 (agent_pg.py)
loss = -torch.min(surr1, surr2) + 1.0 * nn.MSELoss()(state_values, rewards)- 0.01 * entropy
MLDS hw4 (agent_pg.py)
loss_vf = tf.squared_difference(self.rewards + self.gamma * self.v_preds_next, v_preds)
The text was updated successfully, but these errors were encountered: