forked from StarlightSearch/EmbedAnything
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request StarlightSearch#75 from akshayballal95/main
Remove TextEmbed Former-commit-id: 446d095
- Loading branch information
Showing
15 changed files
with
199 additions
and
91 deletions.
There are no files selected for viewing
Some generated files are not rendered by default. Learn more about how customized files appear on GitHub.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,9 @@ | ||
| authors: | ||
| akshay: | ||
| name: Akshay Ballal | ||
| description: Creator of EmbedAnything | ||
| avatar: https://pbs.twimg.com/profile_images/1660187462357127168/6dV9SpLi_400x400.jpg | ||
| sonam: | ||
| name: Sonam Pankaj | ||
| description: Creator of EmbedAnything | ||
| avatar: https://pbs.twimg.com/profile_images/1798985783292125184/L6YQmg1Q_400x400.jpg |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1 @@ | ||
| # All Posts |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,150 @@ | ||
| --- | ||
| draft: false | ||
| date: 2024-01-31 | ||
| authors: | ||
| - akshay | ||
| - sonam | ||
| slug: vector-streaming | ||
| --- | ||
| Introducing vector streaming in EmbedAnything, a feature designed to optimize large-scale document embedding. By enabling asynchronous chunking and embedding using Rust’s concurrency, it reduces memory usage and speeds up the process. We also show how to integrate it with the Weaviate Vector Database for seamless image embedding and search. | ||
|
|
||
|
|
||
| <!-- more --> | ||
|
|
||
| In my previous article [Supercharge Your Embeddings Pipeline with EmbedAnything](https://www.analyticsvidhya.com/blog/2024/06/supercharge-your-embeddings-pipeline-with-embedanything/), I discussed the idea behind EmbedAnything and how it makes creating embeddings from multiple modalities easy. In this article, I want to introduce a new feature of EmbedAnything called vector streaming and see how it works with Weaviate Vector Database. | ||
|
|
||
| ### What is the problem? | ||
|
|
||
| First, let's examine the current problem with creating embeddings, especially in large-scale documents. The current embedding frameworks operate on a two-step process: chunking and embedding. First, the text is extracted from all the files, and chunks/nodes are created. Then, these chunks are fed to an embedding model with a specific batch size to process the embeddings. While this is done, the chunks and the embeddings stay on the system memory. This is not a problem when the files are small, and the embedding dimensions are small. But this becomes a problem when there are many files and you are working with large models and, even worse, multi-vector embeddings. Thus, to work with this, a high RAM is required to process the embeddings. Also, if this is done synchronously, a lot of time is wasted while the chunks are being created, as chunking is not a compute-heavy operation. As the chunks are being made, passing them to the embedding model would be efficient. | ||
|
|
||
| ### Our Solution | ||
|
|
||
| The solution is to create an asynchronous chunking and embedding task. We can effectively spawn threads to handle this task using Rust's concurrency patterns and thread safety. This is done using Rust's MPSC (Multi-producer Single Consumer) module, which passes messages between threads. Thus, this creates a stream of chunks passed into the embedding thread with a buffer. Once the buffer is complete, it embeds the chunks and sends the embeddings back to the main thread, where they are sent to the vector database. This ensures no time is wasted on a single operation and no bottlenecks. Moreover, only the chunks and embeddings in the buffer are stored in the system memory. They are erased from the memory once moved to the vector database. | ||
|
|
||
|
|
||
| 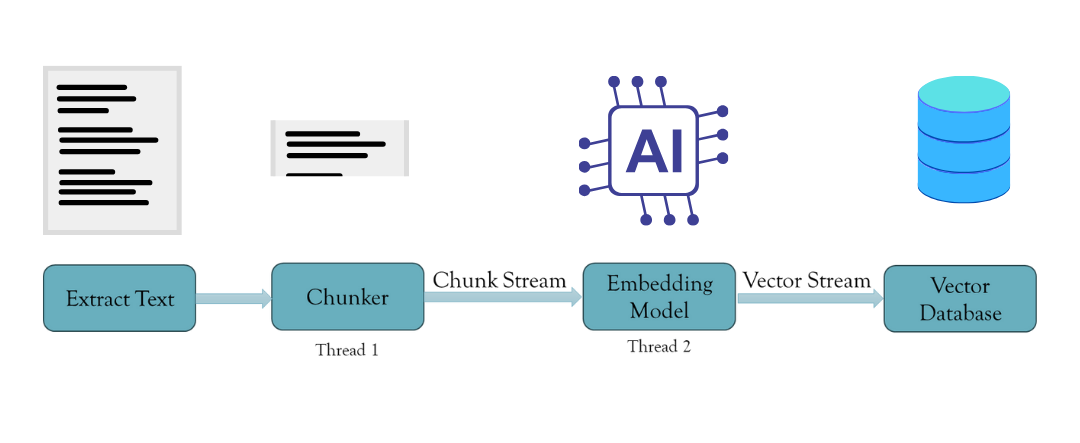 | ||
|
|
||
|
|
||
|
|
||
| ### Example Use Case | ||
|
|
||
| Now, let's see this feature in action. | ||
|
|
||
| With EmbedAnything, streaming the vectors from a directory of files to the vector database is a simple three-step process. | ||
|
|
||
| 1. **Create an adapter for your vector database:** This is a wrapper around the database's functions that allows you to create an index, convert metadata from EmbedAnything's format to the format required by the database, and the function to insert the embeddings in the index. Adapters for the prominent databases are already created and present [here](https://github.com/StarlightSearch/EmbedAnything/tree/main/examples/adapters): | ||
|
|
||
| 2. **Initiate an embedding model of your choice:** You can choose from different local models or even cloud models. The configuration can also be determined to set the chunk size and buffer size for how many embeddings need to be streamed at once. Ideally, this should be as high as possible, but the system RAM limits this. | ||
|
|
||
| 3. **Call the embedding function from EmbedAnything:** Just pass the directory path to be embedded, the embedding model, the adapter, and the configuration. | ||
|
|
||
| In this example, we will embed a directory of images and send it to the vector databases. | ||
|
|
||
| #### Step 1: Create the Adapter | ||
|
|
||
| In EmbedAnything, the adapters are created outside so as to not make the library heavy and you get to choose which database you want to work with. Here is a simple adapter for Weaviate. | ||
|
|
||
| ```python | ||
| from embed_anything import EmbedData | ||
| from embed_anything.vectordb import Adapter | ||
|
|
||
| class WeaviateAdapter(Adapter): | ||
| def __init__(self, api_key, url): | ||
| super().__init__(api_key) | ||
| self.client = weaviate.connect_to_weaviate_cloud( | ||
| cluster_url=url, auth_credentials=wvc.init.Auth.api_key(api_key) | ||
| ) | ||
| if self.client.is_ready(): | ||
| print("Weaviate is ready") | ||
|
|
||
| def create_index(self, index_name: str): | ||
| self.index_name = index_name | ||
| self.collection = self.client.collections.create( | ||
| index_name, vectorizer_config=wvc.config.Configure.Vectorizer.none() | ||
| ) | ||
| return self.collection | ||
|
|
||
| def convert(self, embeddings: List[EmbedData]): | ||
| data = [] | ||
| for embedding in embeddings: | ||
| property = embedding.metadata | ||
| property["text"] = embedding.text | ||
| data.append( | ||
| wvc.data.DataObject(properties=property, vector=embedding.embedding) | ||
| ) | ||
| return data | ||
|
|
||
| def upsert(self, embeddings): | ||
| data = self.convert(embeddings) | ||
| self.client.collections.get(self.index_name).data.insert_many(data) | ||
|
|
||
| def delete_index(self, index_name: str): | ||
| self.client.collections.delete(index_name) | ||
|
|
||
| ### Start the client and index | ||
|
|
||
| URL = "your-weaviate-url" | ||
| API_KEY = "your-weaviate-api-key" | ||
| weaviate_adapter = WeaviateAdapter(API_KEY, URL) | ||
|
|
||
| index_name = "Test_index" | ||
| if index_name in weaviate_adapter.client.collections.list_all(): | ||
| weaviate_adapter.delete_index(index_name) | ||
| weaviate_adapter.create_index("Test_index") | ||
| ``` | ||
|
|
||
|
|
||
| #### Step 2: Create the Embedding Model | ||
|
|
||
| Here, since we are embedding images, we can use the clip model | ||
|
|
||
| ```python | ||
| import embed_anything import WhichModel | ||
|
|
||
| model = embed_anything.EmbeddingModel.from_pretrained_cloud( | ||
| embed_anything.WhichModel.Clip, | ||
| model_id="openai/clip-vit-base-patch16") | ||
|
|
||
| ``` | ||
|
|
||
| #### Step 3: Embed the Directory | ||
|
|
||
| ```python | ||
|
|
||
| data = embed_anything.embed_image_directory( | ||
| "\image_directory", | ||
| embeder=model, | ||
| adapter=weaviate_adapter, | ||
| config=embed_anything.ImageEmbedConfig(buffer_size=100), | ||
| ) | ||
|
|
||
| ``` | ||
|
|
||
| #### Step 4: Query the Vector Database | ||
|
|
||
| ```python | ||
| query_vector = embed_anything.embed_query(["image of a cat"], embeder=model)[0].embedding | ||
| ``` | ||
|
|
||
| #### Step 5: Query the Vector Database | ||
|
|
||
| ```python | ||
| response = weaviate_adapter.collection.query.near_vector( | ||
| near_vector=query_vector, | ||
| limit=2, | ||
| return_metadata=wvc.query.MetadataQuery(certainty=True), | ||
| ) | ||
| ``` | ||
|
|
||
| Check the response; | ||
|
|
||
|
|
||
|  | ||
|
|
||
| Check out the notebook for the code here on colab | ||
|
|
||
| [](https://colab.research.google.com/drive/17vUZEh-ZSpN339pIXSkyxtDHS5Sz6DqD?usp=sharing) | ||
|
|
||
| ### Conclusion | ||
|
|
||
| We think vector streaming is one of the features that will empower many engineers to opt for a more optimized and no-tech debt solution. Instead of using bulky frameworks on the cloud, you can use a lightweight streaming option. Please don't forget to give us a ⭐ on our GitHub repo over here: [EmbedAnything Repo](https://github.com/StarlightSearch/EmbedAnything) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,11 +1,13 @@ | ||
| use embed_anything::text_loader::TextLoader; | ||
| use embed_anything::chunkers::statistical::StatisticalChunker; | ||
| fn main() { | ||
|
|
||
| #[tokio::main] | ||
| async fn main() { | ||
| let text = TextLoader::extract_text("/home/akshay/EmbedAnything/test_files/attention.pdf").unwrap(); | ||
| let chunker = StatisticalChunker{ | ||
| verbose: true, | ||
| ..Default::default() | ||
| }; | ||
| let chunks = chunker._chunk(&text, 32); | ||
| let chunks = chunker._chunk(&text, 32).await; | ||
|
|
||
| } |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.